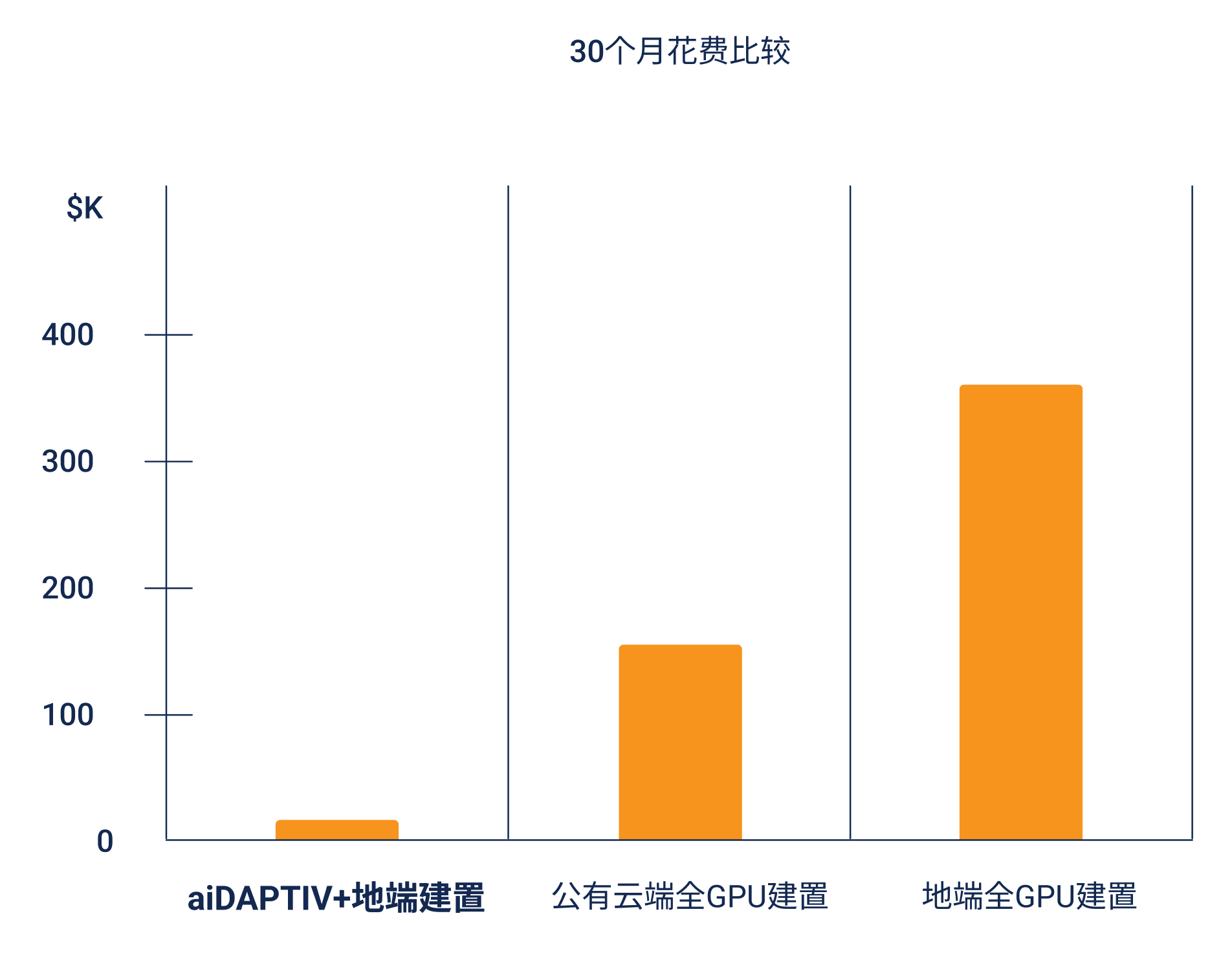
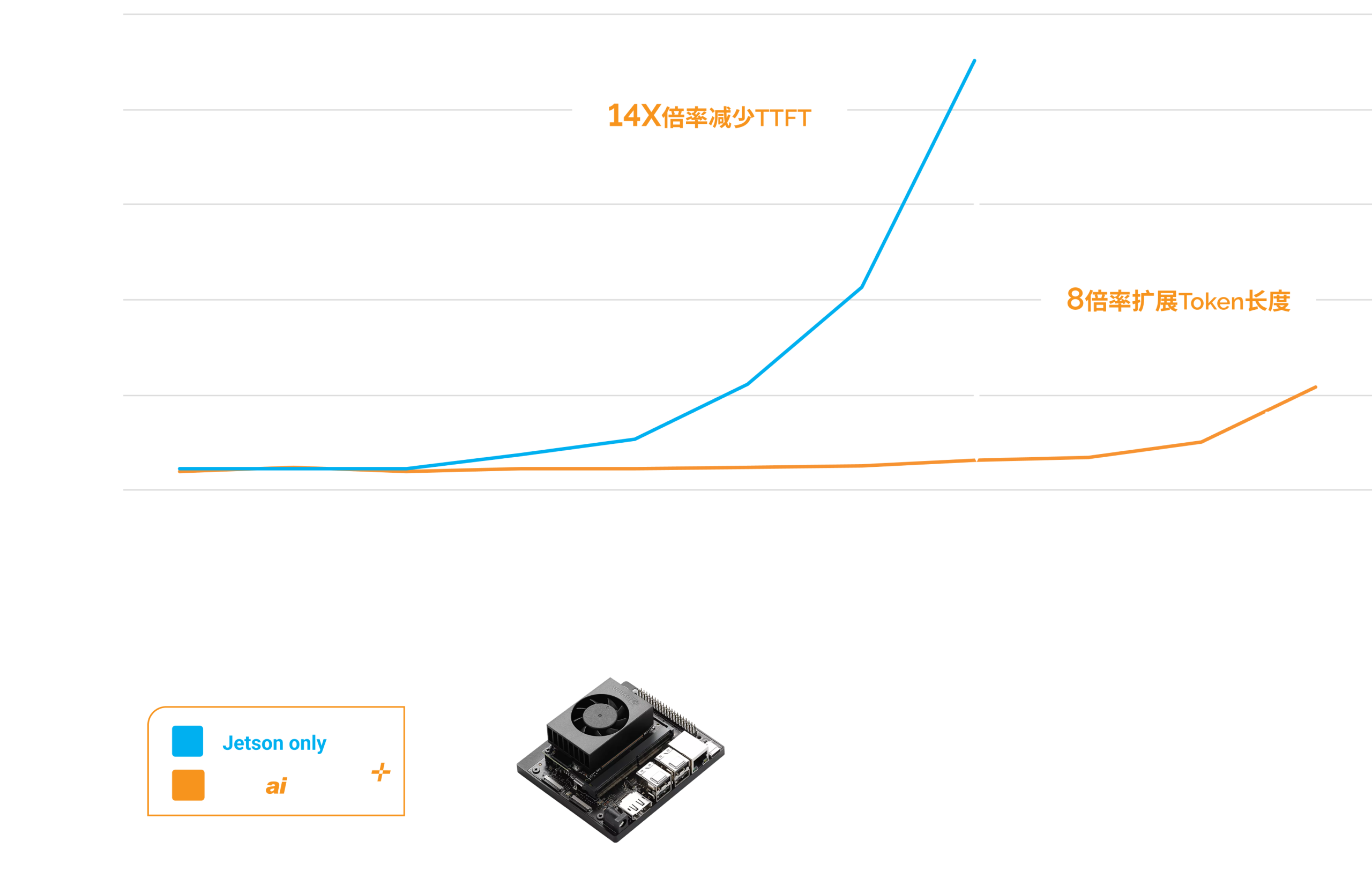
Phison’s dedicated technical support offers end-to-end assistance for aiDAPTIV+ throughout the entire product lifecycle, from initial implementation to on-going operation and optimization.
Our team of experts provides rapid troubleshooting, firmware adjustments, and performance tuning to ensure seamless integration and maximum product efficiency.
With access to our support engineers and cutting-edge tools, Phison’s aiDAPTIV+ customers and partners can accelerate time-to-market while maximizing return on investment for their AI workloads.